Grouped-Query Attention (GQA)
Grouped-Query Attention is a technique developed to address the significant memory requirements of the Key Value (KV) Cache during the inference phase of large language models. The KV Cache is essential because it stores the computed keys and values from previous tokens, allowing the model to avoid recalculating them for each new token and enabling the computation time to increase linearly with input tokens rather than quadratically. However, the size of this cache grows substantially with factors like the number of Transformer blocks, batch size, number of attention heads, attention head size, and context length. This can lead to enormous memory usage, potentially reaching hundreds of gigabytes for large models with long context windows, increasing inference costs and slowing down computations.
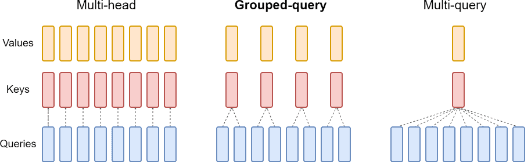
GQA sits conceptually between Multi-Head Attention (MHA) and Multi-Query Attention (MQA).
1. Multi-Head Attention (MHA): In standard MHA, each attention head typically has its own distinct trainable weight matrices (WK and WV) for computing keys and values. This results in different key and value matrices for every single head. Because they are all different, the KV Cache must store the key and value matrices for every attention head, making the number of heads (N) a direct multiplier in the cache size. MHA is considered the best in terms of performance and context understanding because the distinct keys and values allow each head to capture different perspectives and diverse relationships in the data.
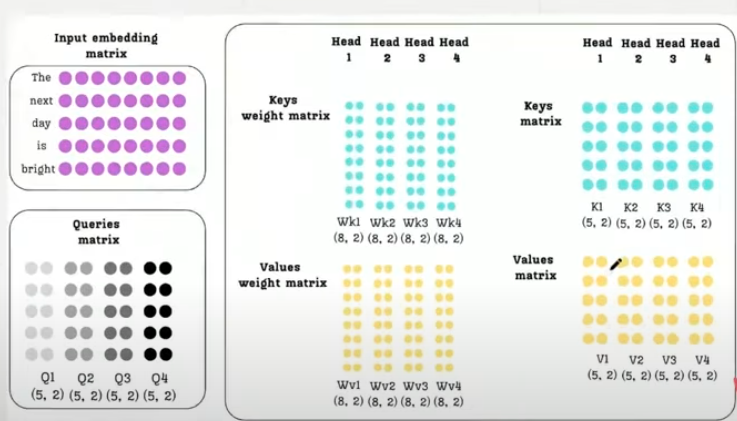
2. Multi-Query Attention (MQA): MQA goes to the opposite extreme to minimise KV Cache memory. In MQA, all attention heads share the same key and value matrices. This means the key matrix for head one is identical to the key matrix for head two, and so on, and the same applies to the value matrices (see above fig). Only the query matrices (Q) remain distinct for each head. The massive advantage of MQA is the reduction in KV Cache size. Since all keys and values are the same across heads, you only need to cache the keys and values for a single head, effectively removing the number of attention heads (N) as a multiplier in the cache size formula. This results in the smallest KV Cache size among the three techniques. However, the significant disadvantage is performance degradation. By forcing keys and values to be identical, MQA severely restricts the diversity that different heads can capture, leading to weaker context understanding.
3. Grouped-Query Attention (GQA): GQA is the compromise. Instead of all heads sharing the same keys and values (like MQA) or every head having unique keys and values (like MHA), GQA proposes to create groups of attention heads, and within each group, the heads share the same key and value matrices. However, the key and value matrices for heads in different groups are different.
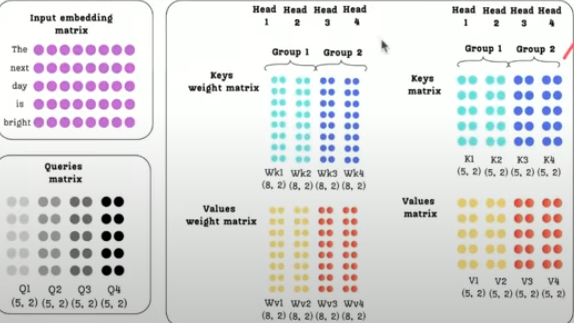
The Core Mechanism of GQA:
The attention heads are divided into
Ggroups.Within each group, the heads share the same trainable WK and WV weight matrices, leading to shared key (K) and value (V) matrices.
Heads in different groups use different WK and WV matrices, resulting in different shared K and V matrices for each group.
The query matrices (Q) remain distinct for each individual attention head, similar to MHA and MQA.
Advantages of GQA:
Reduced KV Cache Memory: GQA reduces the KV Cache size compared to MHA. Since heads within a group share keys and values, you only need to cache the keys and values once per group, not once per head. The KV Cache size now grows with the number of groups (G) instead of the total number of heads (N). If a model has N heads and G groups, the KV Cache size is reduced by a factor of N/G compared to MHA. For example, a model with 128 heads divided into 8 groups would see a KV Cache reduction factor of 128/8 = 16 times compared to MHA. This makes the KV Cache size smaller than MHA but larger than MQA.
Improved Performance over MQA: GQA offers better performance and context understanding than MQA. By allowing different groups to have different keys and values, GQA enables heads in different groups to capture more diversity and different perspectives than MQA, where all heads share the same keys and values.
Disadvantages of GQA:
Larger KV Cache than MQA: The memory savings are not as drastic as MQA, as you still need to cache keys and values for each group, not just a single head.
Lower Performance than MHA: GQA still doesn't achieve the full diversity of MHA, where every head has unique keys and values. Heads within the same group still share the same key-value content, limiting their ability to capture truly distinct perspectives.
In essence, GQA strikes a balance: it provides significant KV Cache memory savings compared to MHA while mitigating the severe performance degradation seen with MQA. Its KV Cache size and performance both lie somewhere in the middle of MHA and MQA.
A prominent example of a model using Grouped-Query Attention is Llama 3, specifically the 8 billion and 70 billion parameter versions, as confirmed by Meta themselves. The source demonstrates this visually by examining the key matrices across different heads in Llama 3. For a model like Llama 3 8B, which reportedly has 32 total attention heads divided into 8 groups (4 heads per group), the source's visualization shows that:
Within a single group (e.g., group 0, heads 1-4), the key matrices are visually identical.
When comparing matrices between different groups (e.g., group 0 vs. group 1), the key matrices are visually different.