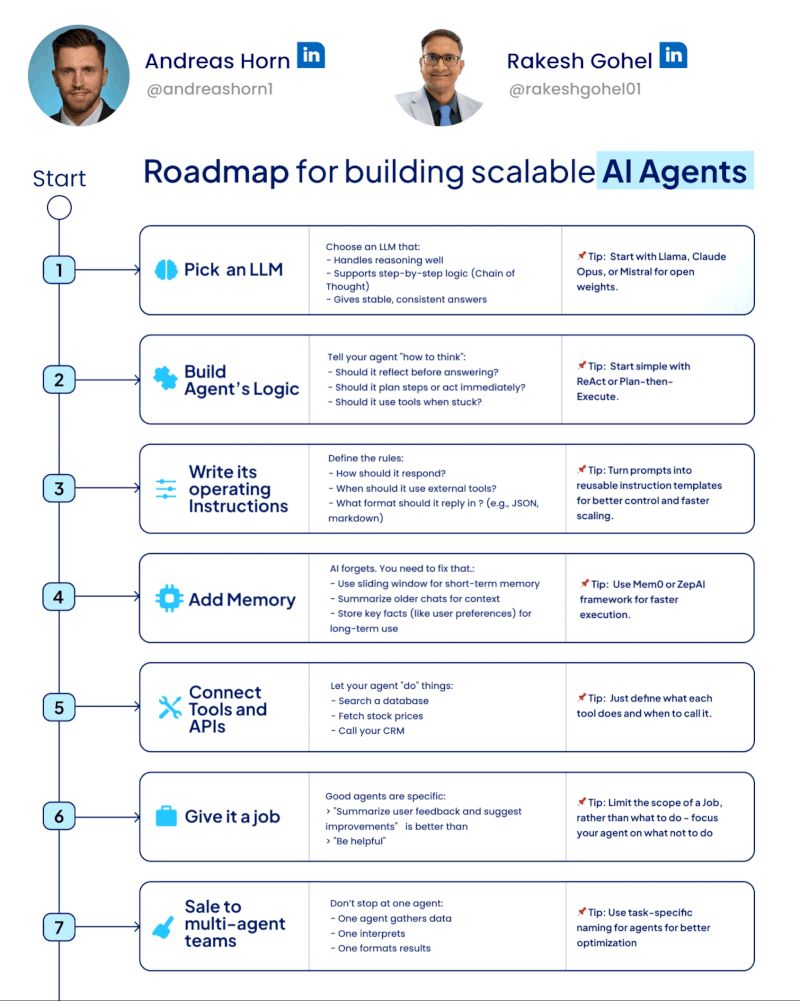
Building Powerful Agents

The development of AI agents represents a significant advancement in how we interact with and leverage Large Language Models (LLMs). These agents are more than just chatbots; they are systems designed to understand goals, make plans, and take actions in the digital or even physical world to achieve those goals with a degree of independence. This summary synthesizes insights from OpenAI, Anthropic, and Google on building effective and reliable AI agents.
Agents = Prompts + LLM + Memory + Tools
1. What is an AI Agent?
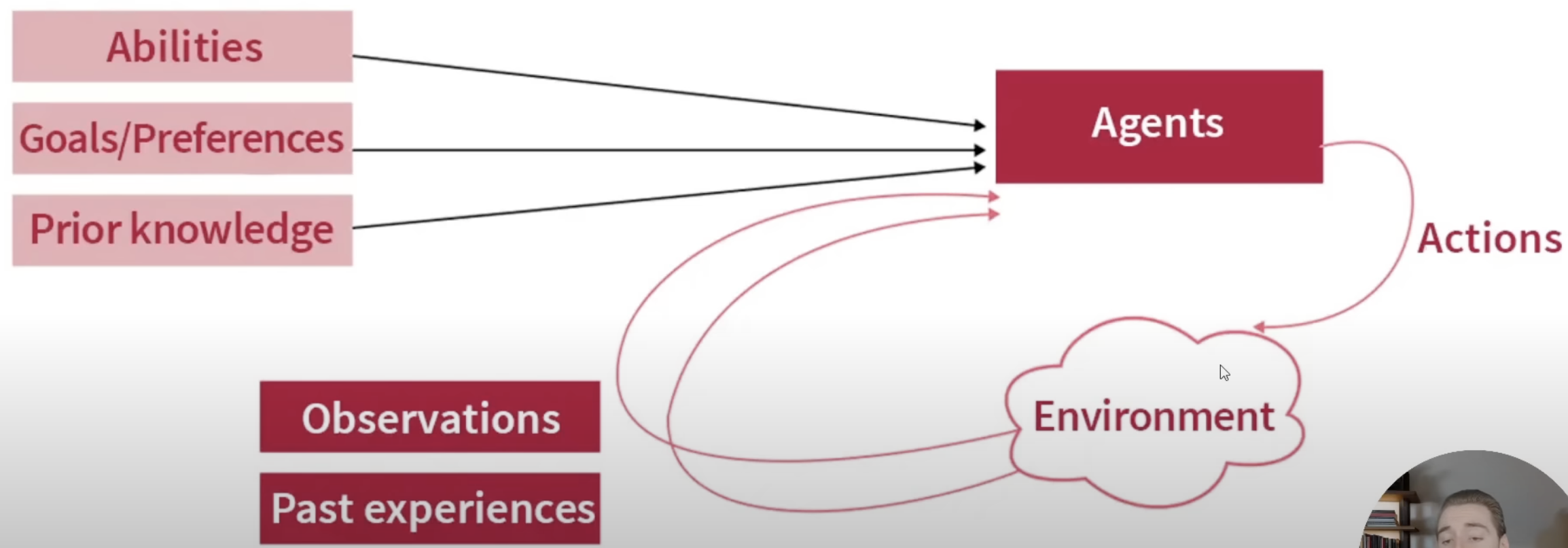
Core Concept: An AI agent is a system, powered by an LLM, that can independently accomplish tasks or perform workflows on a user's behalf. It goes beyond simple, single-turn LLM applications by controlling workflow execution and making decisions.
Key Characteristics:
Goal-Oriented: Understands and pursues a specified objective.
Autonomous/Semi-Autonomous: Operates with a high degree of independence, planning and executing steps.
Tool Use: Interacts with external tools, APIs, and data sources to gather information or perform actions.
Reasoning and Planning: Capable of making decisions, decomposing tasks, and adapting its approach.
Anthropic's Distinction:
Workflows: Systems where LLMs and tools follow predefined code paths.
Agents: Systems where LLMs dynamically direct their own processes and tool usage.
Both are considered "agentic systems".
2. When to Build an Agent
Agents are particularly useful when:
Tasks are complex and involve multiple steps.
A high degree of independence and automation is desired.
Flexibility and model-driven decision-making are needed at scale.
The task involves unstructured data or decisions that are difficult to codify with traditional rule-based systems.
However, it's advised to start with the simplest solution. Optimizing single LLM calls with retrieval and in-context examples might be sufficient for many applications. Agentic systems often trade latency and cost for better task performance, so this trade-off must be considered.
3. Core Components of an Agent
Building an effective agent involves several key components:
The Model (LLM): This is the brain of the agent. It requires strong reasoning capabilities, the ability to follow complex instructions, and learn from feedback. The choice of model depends on the complexity of the task, cost, and latency requirements.
Instructions (Prompt Engineering): Clear, detailed, and unambiguous instructions are crucial for guiding the agent's behavior, defining its persona, setting constraints, and specifying how to use tools. This includes providing context, examples, and desired output formats.
Tools: These are extensions that allow the agent to interact with the outside world, access information beyond its training data, and perform actions. Examples include:
Functions/APIs: Calling external services, databases, or custom code. Maybe MCP
Data Stores/Knowledge Bases: Retrieving information from vector databases, traditional databases, or document repositories (often part of Retrieval Augmented Generation - RAG).
Extensions: Pre-built connections to external services (e.g., Google Search, Google Workspace tools).
Orchestration Layer (Control Logic): This component manages the overall execution flow, coordinating between the model, tools, and memory. It implements the agent's decision-making loop (e.g., plan, action, observation).
Memory: Enables agents to retain information from past interactions and observations, allowing for contextually aware and coherent behavior over time. This can range from short-term context windows to long-term storage in data stores.
4. Agent Architectures and Cognitive Patterns
Agents operate based on cognitive architectures or patterns that define how they reason, plan, and act.
Basic Agent Loop (Conceptual Flow):
1. User Request: The agent receives a goal or task.
2. Planning: The LLM breaks down the task into a sequence of steps or decides on an initial action.
3. Action: The agent executes an action, often by calling a tool.
4. Observation: The agent receives the result or feedback from the action/tool.
5. Reasoning/Reflection: The LLM processes the observation, updates its plan, and decides on the next step. This loop continues until the goal is achieved or a stopping condition is met.
Common Workflow and Orchestration Patterns:
Single Agent: A single LLM instance handles all aspects of the task.
Prompt Chaining: Decomposes a task into a sequence of steps, where each LLM call processes the output of the previous one. Programmatic checks ("gates") can be added to ensure the process stays on track. This is ideal when tasks can be cleanly broken into fixed subtasks.
Routing: Classifies an input and directs it to a specialized LLM or sub-task. Useful for handling distinct categories of tasks or optimizing for cost/speed by using different models for different query types.
Parallelization:
Sectioning: Breaking a task into independent subtasks run in parallel, with outputs aggregated.
Voting: Running the same task multiple times (perhaps with different prompts or settings) to get diverse outputs, which can then be aggregated or selected from.
Orchestrator-Workers: A central LLM (orchestrator) dynamically breaks down complex tasks and delegates them to specialized worker LLMs (subagents), then synthesizes their results. Suited for tasks where subtasks aren't predictable upfront.
Evaluator-Optimizer (Refinement Loop): One LLM call generates a response, while another LLM (or human) evaluates it and provides feedback. The generating LLM then refines its output based on this feedback in an iterative loop. Effective when clear evaluation criteria exist.
Agent Groups (OpenAI):
Hierarchical: A coordinating agent delegates sub-tasks to specialist agents.
Ensemble: Multiple agents perform the same task, and their outputs are aggregated or voted on.
Sequential: Agents operate in a pipeline, each performing a step and passing the result to the next.
Human-in-the-Loop (HITL): Integrating human oversight and intervention at critical decision points or for tasks requiring human judgment.
Advanced Cognitive Architectures (Google):
Chain-of-Thought (CoT): Prompts the LLM to generate intermediate reasoning steps before giving a final answer, improving performance on complex reasoning tasks. Variations include Self-Consistency (generating multiple CoTs and taking the majority answer), Active Prompting, and Multimodal CoT.
ReAct (Reason + Act): Interleaves reasoning traces (thought process) and actions (tool use). The LLM generates a thought about what to do, then an action, receives an observation, and repeats. This allows for dynamic reasoning and planning.
Tree of Thoughts (ToT): The LLM explores multiple reasoning paths simultaneously, like a tree. It can deliberate, backtrack, and evaluate different paths, making it suitable for complex problem-solving where initial steps might be uncertain.
5. Tool Design and Usage ("Agent-Computer Interface" - ACI)
Effective tool design is crucial for agent performance.
Clarity and Simplicity: Tool descriptions, names, and parameters should be clear, unambiguous, and easy for the LLM to understand and use correctly. Anthropic emphasizes treating this as an "Agent-Computer Interface" (ACI) deserving as much effort as Human-Computer Interfaces (HCI).
Provide Examples: Include examples of how to use the tool, edge cases, and input format requirements in the tool's description.
Atomic Tools: Prefer tools that perform a single, well-defined task.
Error Handling: Design tools to return informative error messages that the agent can understand and potentially act upon.
"Poka-yoke" your tools: (A Japanese term meaning "mistake-proofing"). Change arguments or tool design to make it harder for the LLM to make mistakes. For example, requiring absolute filepaths instead of relative ones if the agent might change directories.
Testing: Thoroughly test how the model uses your tools with various inputs to identify and iterate on mistakes.
Tool Formats:
Keep the format close to what the model has seen in its training data (naturally occurring text on the internet).
Avoid "formatting overhead" like requiring the model to keep an accurate count of many lines of code or complex string escaping.
Give the model enough tokens to "think" before it commits to a format.
Types of Tools (Google):
Extensions: Pre-built, ready-to-use connections to external services.
Functions: Developer-defined tools for specific actions, often involving calling APIs or running custom code.
Data Stores: For long-term memory and context retrieval (e.g., vector databases for RAG, SQL databases, etc.).
6. Building and Implementing Agents
Start Simple: Begin with a single agent and simpler orchestration patterns. Only increase complexity (e.g., multi-agent systems) if it demonstrably improves outcomes and simpler solutions fall short.
Iterate and Evaluate: Continuously test and refine your agent. Define clear success metrics and use evaluation frameworks to measure performance. This includes testing prompts, tool usage, and overall task completion.
Frameworks:
Tools like LangChain, Amazon Bedrock's AI Agent framework, Rivet, and Vellum can simplify initial development by handling boilerplate tasks (calling LLMs, defining tools, chaining calls).
However, they can add layers of abstraction, making debugging harder and potentially obscuring underlying prompts and responses. It's crucial to understand the underlying code if using a framework.
Anthropic suggests developers start by using LLM APIs directly, as many patterns can be implemented in a few lines of code.
Google's Vertex AI Agents provide a platform for building and deploying production-grade agents.
Enhancing Model Performance (Google):
Fine-tuning: Adapting a pre-trained model to a specific task or dataset.
Reinforcement Learning from Human Feedback (RLHF): Improving model behavior based on human preferences.
RAG Tuning: Optimizing the retrieval and generation components in RAG systems.
7. Guardrails and Safety
Ensuring agents operate safely, predictably, and ethically is paramount.
Input/Output Filtering: Validate and sanitize inputs to agents, and filter outputs to prevent harmful or inappropriate content.
Tool Access Control: Limit which tools an agent can access and what actions it can perform. Use the least privileged access principle.
Confirmation and Approval: Require user confirmation for sensitive actions.
Rate Limiting and Cost Control: Implement mechanisms to prevent abuse and manage operational costs.
Human Oversight and Intervention (HITL): Design for human review and the ability to intervene or take over if the agent fails or behaves unexpectedly.
Logging and Monitoring: Keep detailed logs of agent actions and decisions for debugging, auditing, and performance analysis.
Sandboxed Environments: Test extensively in sandboxed environments before deploying to production, especially for autonomous agents.
8. Common Use Cases
Customer Support: Handling queries, providing information, and performing actions like issuing refunds or updating tickets. Agents can use tools to access customer data and knowledge bases.
Coding and Software Development: Assisting with code generation, debugging, refactoring, and even autonomously solving coding tasks based on issue descriptions. Verifiability through automated tests makes this a strong use case.
Automating Workflows: Booking reservations, managing calendars, sending emails, generating reports, and other multi-step business processes.
Data Analysis and Insights: Processing and analyzing large datasets to extract insights and answer questions.
Personal Assistants: Managing tasks, providing information, and interacting with various digital services on a user's behalf.
9. Guiding Principles for Effective Agent Development
Simplicity: Maintain simplicity in the agent's design. Avoid unnecessary complexity.
Transparency: Prioritize transparency by explicitly showing the agent’s planning and reasoning steps. This aids in debugging and builds trust.
Iterative Development: Start small, validate with real users, and incrementally add capabilities.
Robust Tooling: Carefully craft the agent-computer interface (ACI) through thorough tool documentation, clear design, and rigorous testing.
Strong Foundations: Pair capable models with well-defined tools and clear, structured instructions.
Focus on the Right System: Success isn't about building the most sophisticated system, but the right system for the specific needs and context.
By following these guidelines and principles, developers can build AI agents that are powerful, reliable, maintainable, and ultimately, trustworthy.
Below is the step by step process on how you can start with the process of buiding powerful agents!
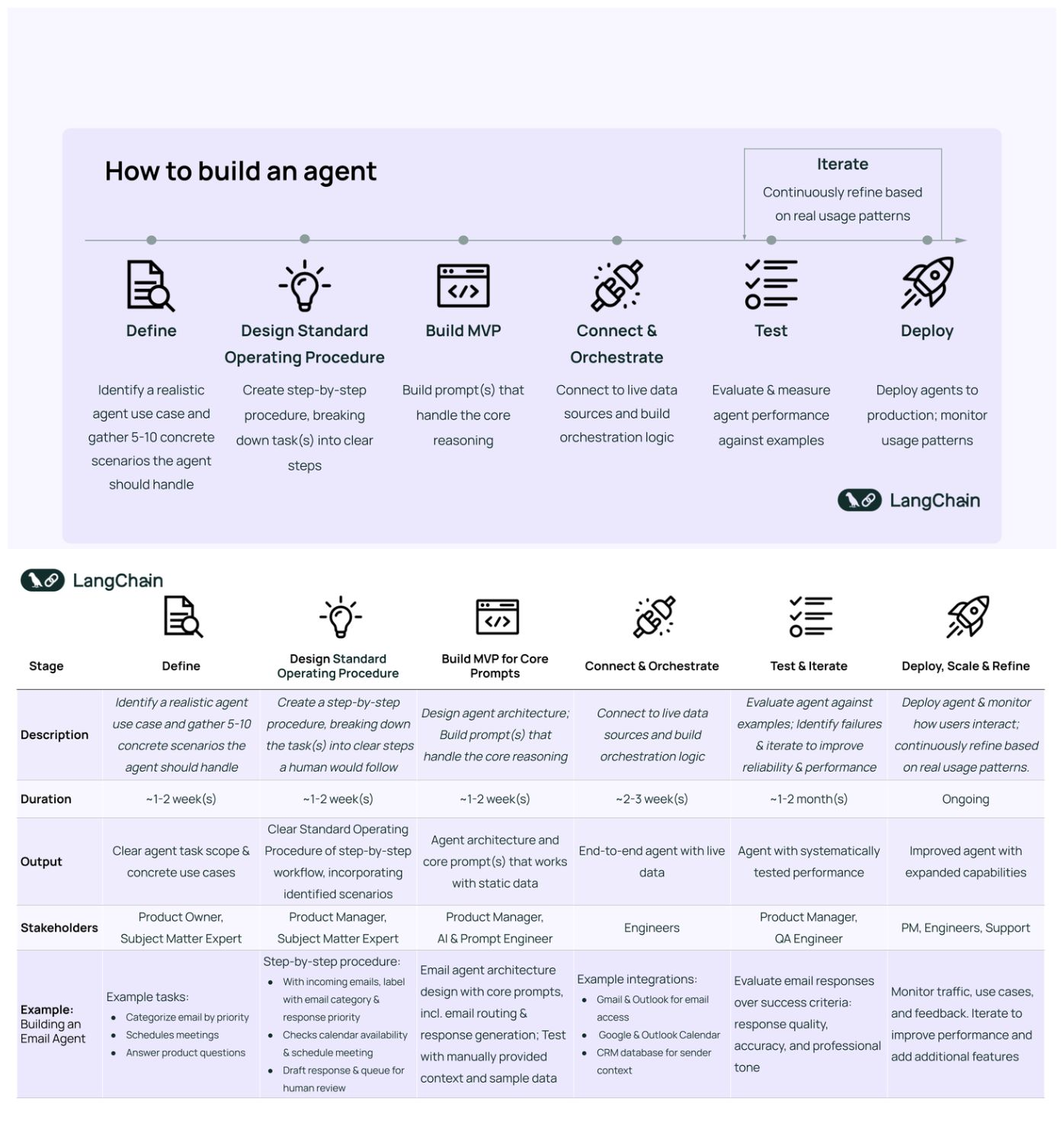
[Bonus] - Here is another helpful roadmap for beginners.